Extracting and Parsing Web Data With Python and BeautifulSoup
Sorin-Gabriel Marica on Jul 13 2021
Web scrapers are valuable tools that help you extract specific information from a website. Theoretically, you could do this manually, but web scraping allows you to process vast amounts of data more efficiently and productively.
One of the most popular programming languages for web scraping is Python. This language comes with the library BeautifulSoup, which simplifies the process. Together, this duo makes web scraping a lot easier than in other languages.
In my personal opinion, using BeautifulSoup is the easiest way to build a simple web scraper from scratch. If you want to learn more about this, read on because I’ll show you how to create your own web scraper using Python and BeautifulSoup.
An overview of BeautifulSoup
BeautifulSoup, as stated in their documentation, is a python library for pulling data out of HTML and XML files. So, you can use Python to extract the HTML content from a website and then use BeautifulSoup to parse that HTML to get just the relevant information.
The main advantage of using BeautifulSoup it’s the simple syntax that it offers. With this library, you can navigate the DOM tree, search for specific elements, or modify HTML content. All of these benefits made it the most popular python library for parsing HTML and XML documents.
Installation
To install BeautifulSoup, you should check the guide from here, as the installation is different based on the machine you use. In this article, I’m using a Linux system and only need to run the following command:
pip install beautifulsoup4
If you use python3, you might need to install the library by using the following command instead:
pip3 install beautifulsoup4
Keep in mind that my machine already has python3 installed. If you’re new to Python, you can find a guide on how to install it here. Also, you should check out our ultimate guide to building a web scraper with python for even more information on the topic.
Building a scraper with BeautifulSoup
Now, if everything went smoothly, we’re ready to begin building our own scraper. For this article, I chose to retrieve the top 100 movies of all time from RottenTomatoes and save everything in both JSON and CSV formats.
Retrieving the page source
To warm up and get familiar with BeautifulSoup, we will first retrieve the full HTML of the page and save it in a new file called “page.txt”.
If you want to see the HTML source of any page, you can do that in Google Chrome by pressing CTRL+U. This will open a new tab, and you will see something like this:
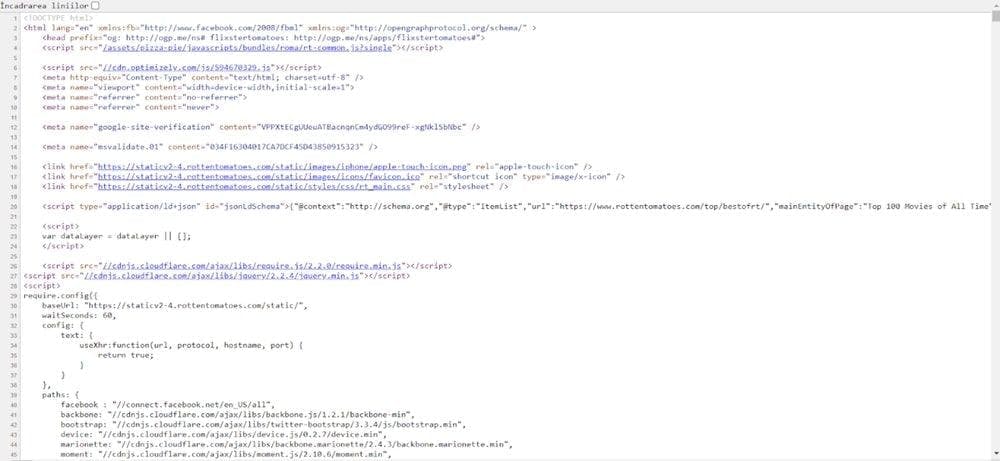
To get the same source with BeautifulSoup and Python, we can use the following code:
import requests
from bs4 import BeautifulSoup
scraped_url = 'https://www.rottentomatoes.com/top/bestofrt/'
page = requests.get(scraped_url)
soup = BeautifulSoup(page.content, 'html.parser')
file = open('page.txt', mode='w', encoding='utf-8')
file.write(soup.prettify())
In this code, we make a request to the RottenTomatoes page and then add all the page’s content in a BeautifulSoup object. The only usage for BeautifulSoup in this example is the final function called “prettify()”, which formats html code to make it easier to read.
To understand the function better, for this HTML code “<div><span>Test</span></div>”, prettify, will add the tabulations and transform it in this formatted code:
<div>
<span>
Test
</span>
</div>
The final result of the code is creating a file called page.txt that contains the entire page source of our link:
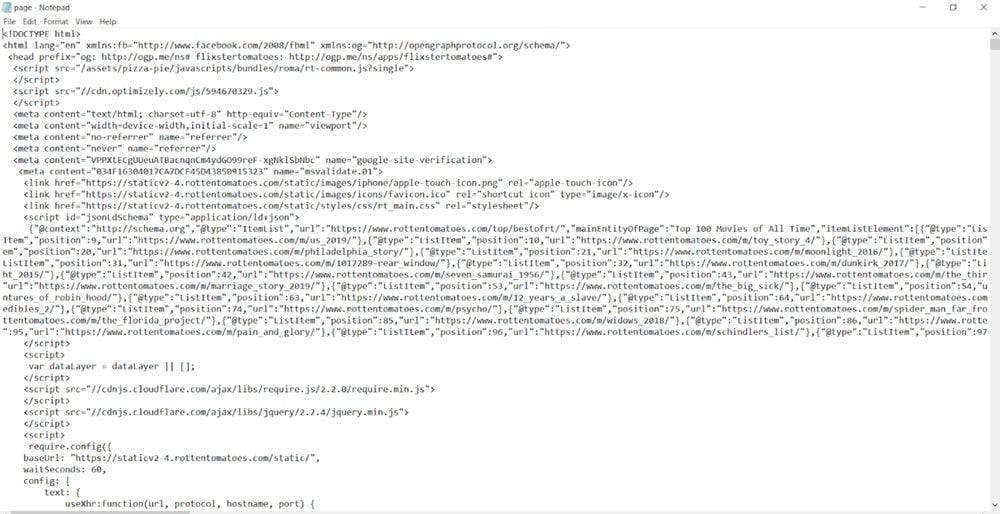
You should note that this is the page source before any Javascript code is executed. Sometimes websites may choose to change their page content dynamically. For these cases, the page source will look different than the actual content displayed to the user. If you need your scraper to execute Javascript, you can read our guide on building a web scraper with Selenium, or you can use WebScrapingAPI, our product that takes care of this issue for you.
Getting the web data
If you look in the previous page source, you will see that you can find the names of the movies and their rating. Fortunately for us, RottenTomatoes does not load the movies list dynamically, so we can go ahead and scrape the needed information.
First, we inspect the page and see how the HTML is structured. To do that, you can right-click on a movie title and choose the option “Inspect Element”. The following window should show up:
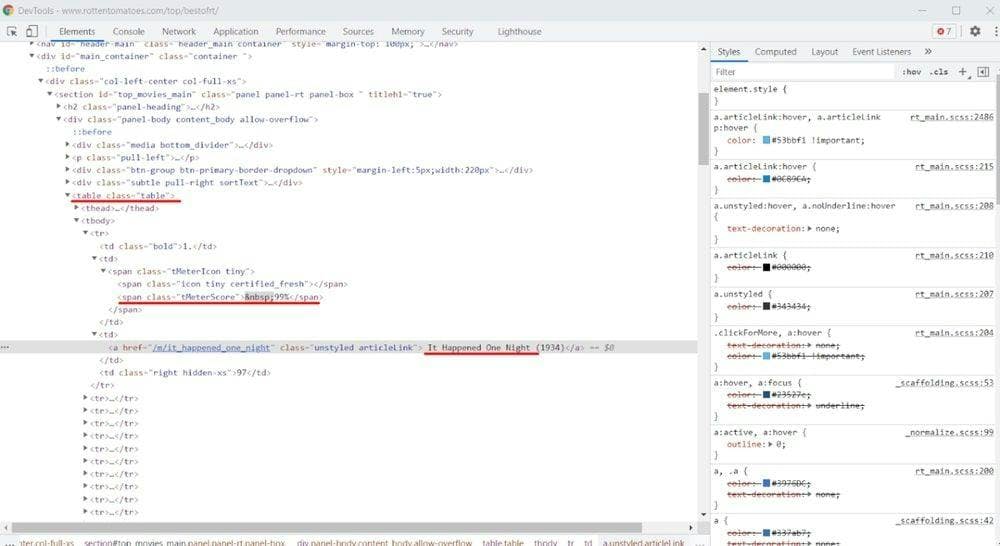
I used the red line to highlight the useful information from this image. You can see that the page displays the top movies in a table and that there are four cells on each table row (<tr> element).
The first cell contains the movie’s position, the second has information about the ratings (element with tMeterScore class), the third includes the movie’s title, and the last cell gives us the number of reviews.
Knowing this structure, we can now start extracting the information we need.
import requests
from bs4 import BeautifulSoup
links_base = 'https://www.rottentomatoes.com'
scraped_url = 'https://www.rottentomatoes.com/top/bestofrt/'
page = requests.get(scraped_url)
soup = BeautifulSoup(page.content, 'html.parser')
table = soup.find("table", class_="table") # We extract just the table code from the entire page
rows = table.findAll("tr") # This will extract each table row, in an array
movies = []
for index, row in enumerate(rows):
if index > 0: # We skip the first row since this row only contains the column names
link = row.find("a") # We get the link from the table row
rating = row.find(class_="tMeterScore") # We get the element with the class tMeterScore from the table row
movies.append({
"link": links_base + link.get('href'), # The href attribute of the link
"title": link.string.strip(), # The strip function removes blank spaces at the beginning and the end of a string
"rating": rating.string.strip().replace(" ", ""), # We remove from the string and the blank spaces
})
print(movies)
When running this code, you should get a result like this:
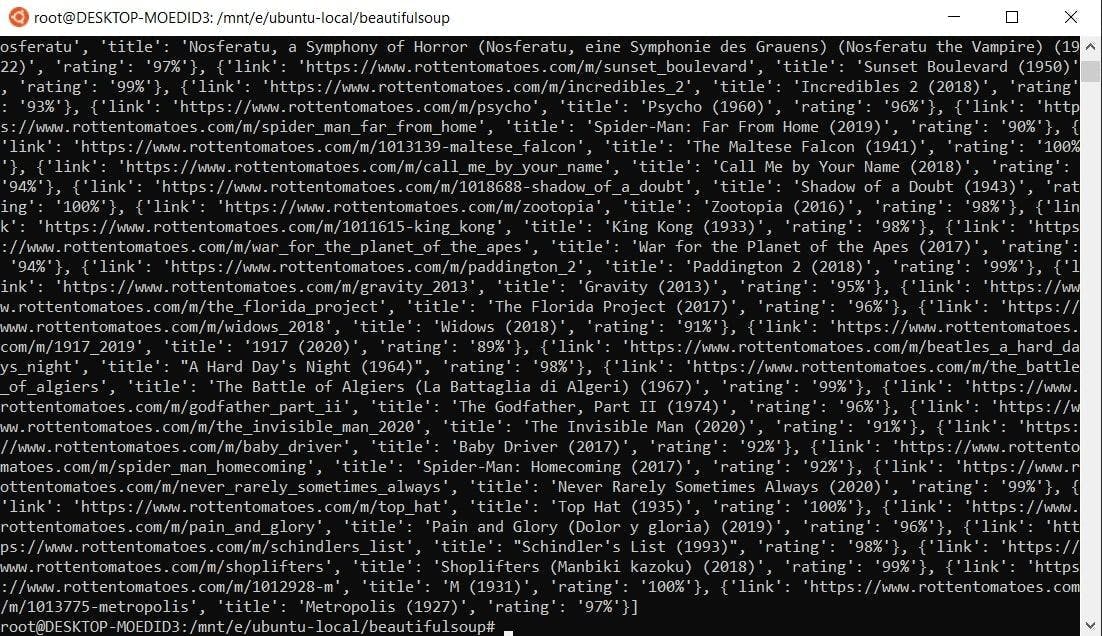
In this example, we are extracting the table contents and looping through the table rows. Since the first row only contains the column names, we will skip it.
On the rest of the rows, we continue the process by extracting the anchor (<a>) element and the span element with the class “tMeterScore”. Having them, we can now retrieve the information needed.
The movie’s title is inside the anchor element, the link is the attribute “href” of the anchor, and the rating is inside the span element with the class “tMeterScore”. We just create a new dictionary for each row and append it to our list of movies.
Saving the web data
So far, the scraper has retrieved and formatted the data, but we only displayed it within the terminal. Alternatively, we can save the information on our computer as a JSON or as a CSV. The complete code of the scraper (including creating a local file) is:
import requests
from bs4 import BeautifulSoup
import csv
import json
links_base = 'https://www.rottentomatoes.com'
scraped_url = 'https://www.rottentomatoes.com/top/bestofrt/'
page = requests.get(scraped_url)
soup = BeautifulSoup(page.content, 'html.parser')
table = soup.find("table", class_="table") # We extract just the table code from the entire page
rows = table.findAll("tr") # This will extract each table row from the table, in an array
movies = []
for index, row in enumerate(rows):
if index > 0: # We skip the first row since this row only contains the column names
link = row.find("a") # We get the link from the table row
rating = row.find(class_="tMeterScore") # We get the element with the class tMeterScore from the table row
movies.append({
"link": links_base + link.get('href'), # The href attribute of the link
"title": link.string.strip(), # The strip function removes blank spaces at the beginning and the end of a string
"rating": rating.string.strip().replace(" ", ""), # We remove from the string and the blank spaces
})
file = open('movies.json', mode='w', encoding='utf-8')
file.write(json.dumps(movies))
writer = csv.writer(open("movies.csv", 'w'))
for movie in movies:
writer.writerow(movie.values())
Scraping Even Further
Now that you have all the info, you can choose to go further into scraping. Remember that each movie has a link. You could continue by scraping the movie pages and extract even more information about them.
For example, if you check the movie page It Happened One Night (1934), you can see that you could still scrape helpful information such as the audience score, the movie duration, genre, and so on.
However, making all these requests in a short period looks very unusual and could lead to CAPTCHA validations or even IP blocks. To avoid that, you should use rotating proxies so that the traffic sent will look natural, and it will come from multiple IPs.
Other features of BeautifulSoup
While our RottenTomatoes scraper is complete, BeautifulSoup still has a lot to offer. Whenever you work on a project, you should keep the documentation link open so that you can quickly look for a solution when you’re stuck.
For example, BeautifulSoup permits navigating the DOM tree of the page:
from bs4 import BeautifulSoup
soup = BeautifulSoup("<head><title>Title</title></head><body><div><p>Some text <span>Span</span></p></div></body>", 'html.parser')
print(soup.head.title) # Will print "<title>Title</title>"
print(soup.body.div.p.span) # Will print "<span>Span</span>"
This feature can help you when you need to select an element that cannot be identified by its attributes. In that case, the only way to find it is by the structure of the DOM.
Another cool thing about BeautifulSoup is that you can modify the page source:
from bs4 import BeautifulSoup
soup = BeautifulSoup("<head><title>Title</title></head><body><div><p>Some text <span>Span</span></p></div></body>", 'html.parser')
soup.head.title.string = "New Title"
print(soup)
# The line above will print "<head><title>New Title</title></head><body><div><p>Some text <span>Span</span></p></div></body>"
This can be invaluable if you want to create a service that allows users to optimize their pages. For example, you can use the script to scrape a website, get the CSS, minify it, and replace it in the HTML source. The possibilities are endless!
Always scrape smart
I really want you to remember this: using Python and Beautifulsoup for web scraping is an excellent idea. It makes the process much easier compared to other programming languages.
The scraper that we built to retrieve the best-rated movies of all time from RottenTomatoes can be coded in just a few minutes, and you can even use it along with the IMDB scraper from our ultimate guide for scraping with PHP.
However, some websites are more accessible to scrapers than others. While the project from this article is simple and fun, some are anything but. Sometimes websites do everything in their power to prevent their content from being scraped.
In certain situations, the only way to scrape content is by masking your work with multiple IPs and a real browser. For this type of situation, we created WebScrapingAPI, a powerful solution that offers rotating proxies, Javascript rendering, and it allows you to scrape any website you want with the minimum amount of headaches!
Don’t just take my word for it, try it yourself! You can start your free trial right now and get 5000 API calls without having to give out any sensitive data like your credit card details.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Discover how to efficiently extract and organize data for web scraping and data analysis through data parsing, HTML parsing libraries, and schema.org meta data.

Learn how to use proxies with Axios & Node.js for efficient web scraping. Tips, code samples & the benefits of using WebScrapingAPI included.