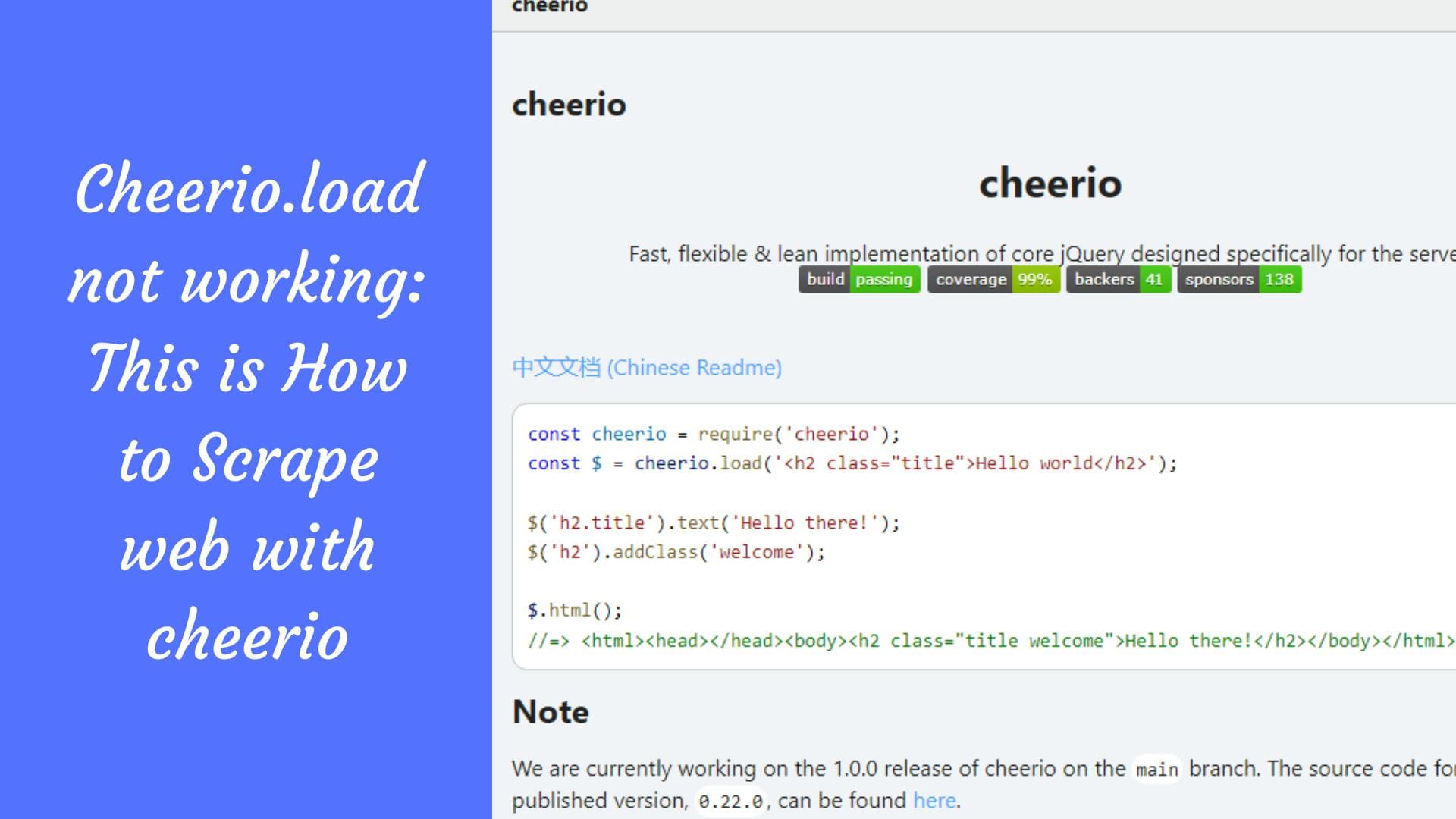
Extracción de datos de páginas web en Node con Cheerio: ¿cómo se hace?
En esta sección en particular, aprenderás a extraer datos de una página web con la ayuda de Cheerio. Pero antes de optar por este método de extracción, debes contar con los permisos necesarios. De lo contrario, podrías infringir la privacidad, violar los derechos de autor o incumplir los términos de servicio.
Aprenderás a extraer el código ISO 3166-1 alpha-3 de todos los países y otras jurisdicciones. Encontrarás los datos de los países en la sección de códigos de la página ISO 3166-1 alpha-3. ¡Empecemos!
Paso 1: Crear un directorio de trabajo
Aquí, debes crear un directorio para el proyecto ejecutando el comando «mkdir learn-cheerio» en el área de la terminal. Este comando en concreto creará un directorio, que se llamará «learn-cheerio», aunque también puedes darle el nombre que quieras
En este paso, crearás un directorio para tu tarea ejecutando un comando en la terminal. El comando creará un directorio llamado learn-cheerio. Puedes darle otro nombre si lo deseas.
Seguramente verás una carpeta con el nombre «learn-cheerio» creada tras ejecutar correctamente los elementos seleccionados o el comando «mkdir learn-cheerio». Una vez creado el directorio y tras cargar con éxito los recursos externos, debes abrir el directorio y un editor de texto para inicializar el proyecto.
Paso 2: Inicialización del proyecto
Para asegurarte de que Cheerio se implementa correctamente en este proyecto, debes navegar hasta el directorio del proyecto y, a continuación, inicializarlo. Solo tienes que abrir el directorio con el editor de texto que prefieras y, a continuación, inicializarlo ejecutando el comando «npm init -y». Una vez completado este proceso, puedes crear un archivo «package.json» en el directorio raíz del proyecto.
Paso 3: Instalar las dependencias
En esta sección, instalarás las dependencias del proyecto ejecutando el comando «npm install Axios cheerio pretty».
Cuando utilices este comando, tardará un poco en cargarse, así que ten paciencia. Una vez que hayas ejecutado el comando correctamente, podrás registrar tres dependencias dentro del archivo package.json, justo debajo de la sección de dependencias.
La primera dependencia se llama «Axios», la segunda es «Cheerio» y la última es «Pretty». Axios es un conocido cliente HTTP que funciona en el navegador y en Node. Lo necesitarás porque Cheerio se considera un analizador de marcado.
Por lo tanto, para asegurarte de que Cheerio pueda analizar el marcado y extraer los datos que necesitas, debes utilizar
Para garantizar que Cheerio pueda analizar el marcado y extraer los datos que necesitas, debes utilizar Axios para obtener el marcado del sitio web. Si lo deseas, puedes utilizar otro cliente HTTP para recuperar el marcado. No tiene por qué ser necesariamente Axios.
«Pretty», por otro lado, es un paquete de npm que embellece el marcado para que sea totalmente legible cuando se imprime en la terminal.
Paso 4: Examina la página web que deseas extraer
Justo antes de extraer los datos de la página web, primero debes comprender bien la estructura de datos HTML resultante de la página. En esta sección
Antes de extraer datos de una página web, es fundamental comprender la estructura HTML de la página de la que vas a extraer los datos. En Wikipedia, ve al código ISO 3166-1 alpha-3. Debajo de la sección «código actual», encontrarás una lista de países y sus códigos.
Ahora, solo tienes que abrir DevTools pulsando la combinación de teclas «CTRL + SHIFT + I». También puedes hacer clic con el botón derecho y seleccionar la opción «Inspeccionar». Aquí tienes una imagen que muestra cómo aparece la «lista» en DevTools
Paso 5: Escribe el código para extraer los datos
Ahora, tienes que escribir el código para extraer los datos. Para empezar, debes ejecutar «touch app.js» para compilar el archivo app.js. Si ejecutas este comando correctamente, podrás crear el archivo app.js dentro del directorio del proyecto sin ningún error.
Al igual que con todos los demás paquetes de Node, tienes que instalar pretty, Cheerio y anxious antes de empezar a utilizarlos. Para ello, debes añadir el siguiente código:
const axios = require ["axios"]
const Cheerio = require ["cheerio"]
const pretty = require ["pretty"]
Asegúrate de incluir estos códigos justo al principio del archivo app.js. Asegúrate de tener un buen conocimiento de Cheerio justo antes de extraer los datos. Puedes analizar el marcado manipulando la estructura de datos resultante. Hacerlo te ayudará a aprender la sintaxis de Cheerio y también el proceso habitual. Aquí está el marcado del elemento UL que contiene los elementos LI:
const URL markup = `
<ul class ="fruits">
<li class="frutis__mango"> Mango </li>
<li class="fruits__apple"> Manzana </li>
</ul>
Puedes añadir fácilmente este comando de variable concreto al archivo app.js.