En resumen: ¿Qué son los proxies ISP? Son direcciones IP residenciales estáticas alojadas en un centro de datos. Los sistemas de detección ven un ASN residencial, pero tú obtienes el rendimiento de un centro de datos. Son la opción adecuada cuando las sesiones, la vinculación de cuentas y una tarificación predecible por IP son más importantes que el alcance geográfico puro.
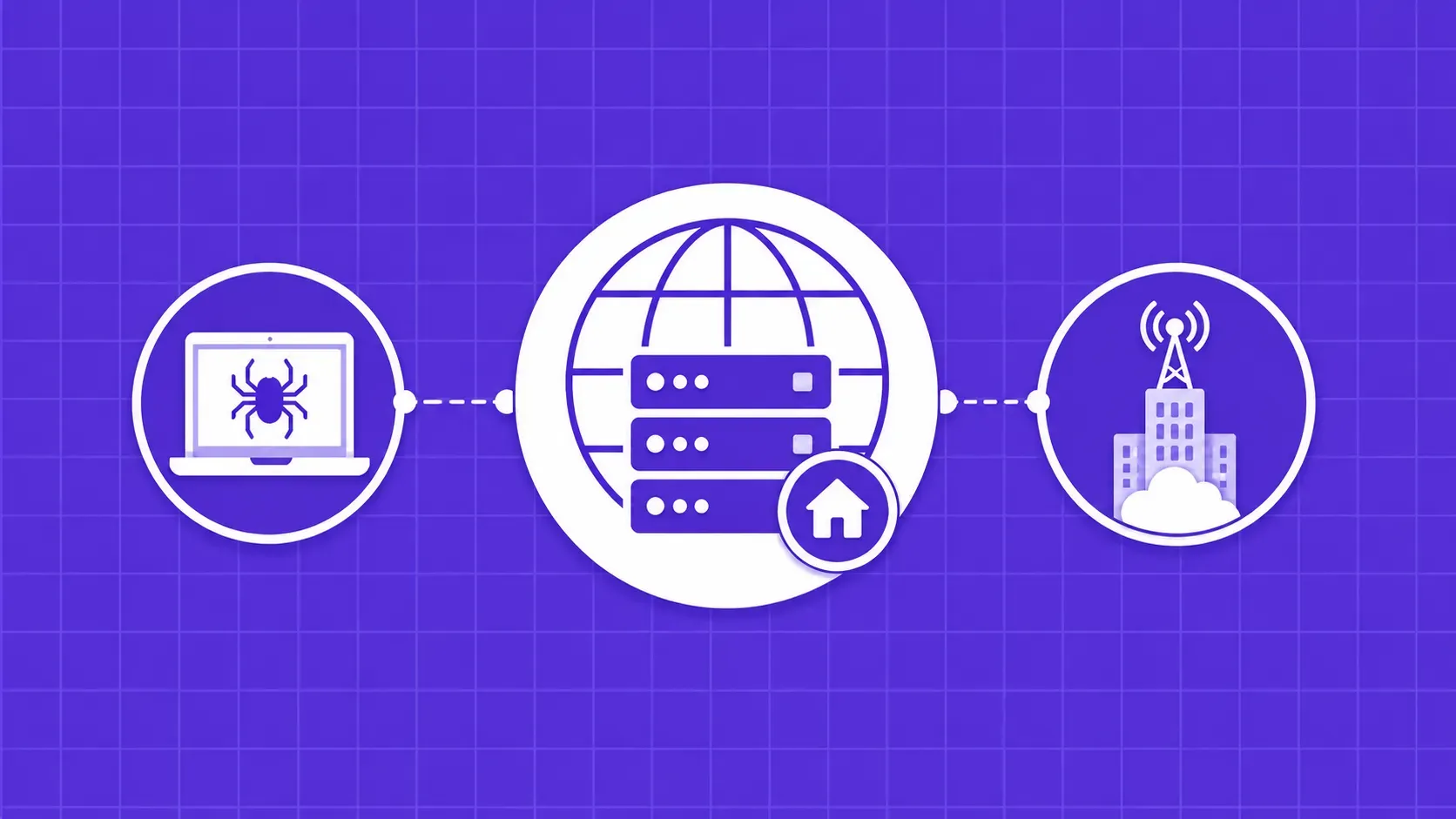
Entonces, ¿qué son los proxies ISP y por qué los profesionales están trasladando las cargas de trabajo de los grupos residenciales rotativos a una IP estática alojada en un centro de datos? A grandes rasgos, un proxy ISP es un servidor proxy que se encuentra dentro de un centro de datos, pero que expone una dirección IP asignada por un proveedor de servicios de Internet real. Los sistemas de detección ven el tráfico procedente de un ASN residencial, mientras que tu código obtiene el ancho de banda y el perfil de latencia de la infraestructura en la nube.
El resto del mercado de proxies se divide en dos categorías más conocidas: proxies de centro de datos (baratos y rápidos, pero fáciles de detectar porque muchos usuarios comparten las mismas IP) y proxies residenciales (IP fiables que se enrutan a través de conexiones domésticas reales, pero más lentas y con tarificación por gigabyte). Los proxies ISP se sitúan en un término medio. A veces se les denomina proxies residenciales estáticos porque la IP pertenece a un bloque de un ISP real, pero se mantiene igual en todas las solicitudes.
Si estás creando procesos de scraping, monitores de SEO, escaneos de verificación de anuncios o flujos de trabajo sociales con múltiples cuentas, la respuesta a qué son los proxies ISP y cuándo utilizarlos determina directamente la tasa de bloqueo, el rendimiento y la estabilidad de la sesión.



